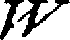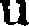Réalisation d'un OCR (écrit en Python) pour convertir la flore du département des hautes Pyrénées (par l'abbé Dulac) à partir de PDF vers HTML.
A gauche le pdf tel que téléchargé depuis la bibliothèque du jardin botanique Madrid
A droite le résultat obtenu par l'OCR décrit tel que publié sur ce site.
Les adaptations du logiciel sont présentées ainsi qiue les étapes principales pour la réalisation de cet OCR.
CHOIX DU LOGICIEL
Après avoir évalué les possiblités de ABB.Finereader6,des OCR intégrés dans les pdf viewer,de TESSERACT et de OCROPUS, j'ai opté pour GAMERA (gamera-3.2.6.win32-py2.5.exe) pour ses interfaces utilisateurs
téléchargeable_ici
GAMERA en très bref.
Ce logiciel, écrit en Python, permet de numériser des images, de détecter les caractères du texte; il permet aussi de définir des modèles de caractères (le classifier) ainsi que les critères qui permettent de classer un glyph comme appartenant à un de ces modèles.Les fonctions en python sont accessibles et modifiables; un outil incorporé permet de rajouter du code en C++, et de le convertir automatiquement en Python.
BUGS?
- Le programme présente une fuite de mémoire lors de l'appel de la fonction Get(x,y) pour accéder aux pixels (Gamera tutorial §2.2) .
J'ai contourné ce bug par l'utilisation du module python "pil_io" et emploi de ces lignes en remplacement de Get.
from gamera.plugins import pil_io
image_pil=image.to_greyscale().to_pil()
pix_en_cours=image_pil.getpixel((i,j))
- Lorsque plus de 4000 glyphs sont présents dans le
classifier interactif et dans la page en cours , il se produit une ereur "Couldn't select a bitmap into wxMemoryDC".
Pour lever cette erreur j'ai transformé la grille de l'interface interactif par une grille basée sur une table (
wxGridTableBase) dans le module gamera_display et les modules y faisant appel;
Je me suis inspiré des exemples donnés dans "wxPython2.8-win32-docs-demos-2.8.11.0.exe"
téléchargeable à
iciclass MultiImageDisplay(gridlib.Grid):
self._table = MegaTable(data_grid,self)
self.SetTable(self._table)
De cette façon, plus de 20000 glyphs peuvent être visualisés sans problème.
- Lors de l'enregistrement de <property> au format .xml, la longueur de la ligne est limitée et le contenu de la propriété réparti sur plusieurs lignes (si dépasse la longueur d'une ligne xml);
<property name="origine" type="str">0.106,esp.bold.l; SOURCE
0.317,loc.l;</property>
au lieu de
<property name="origine" type="str">0.106,esp.bold.l; SOURCE 0.317,loc.l;</property>
ce découpage n'est pas annulé lors de l'ouverture du fichier. Il en résulte des caractères inutiles et une relecture (visuelle ou par programme) de la propriété délicate.
J'ai rajouté un bout de programme pour éviter ce problème.
def elague_prop(la_prop):
avant=str(la_prop).replace('\n',' ')
sans_rien=""
while (1):
sans_rien=avant.replace(' ',' ')
if sans_rien==avant:
break
avant=sans_rien
return sans_rien
def purifie(liste_glyphs):
for le_glyph in liste_glyphs:
for y in le_glyph.properties.iterkeys() :
le_glyph.properties[y]=elague_prop(le_glyph.properties[y])
return liste_glyphs
et remplacé partout
gamera_xml.LoadXML() par
purifie(gamera_xml.LoadXML())
CONSTITUTION DU CLASSIFIER (k=1) - CHOIX DES CRITERES (FEATURES)
J'ai utilisé les features intégrés dans Gamera plus quelques critères spécifiques, comme, par exemple, un critère pour mieux différencier 'u' de 'n' et 'c' de 'e'

.
Le poids des différents features a été optimisé par le module BIOLLANTE intégré dans Gamera et conduit a une confiance de 97%. (cela signifie que dans 97% des cas les critères appliqués à un modèle permettent au classifier de l'identifier correctement).
Les algorithmes pour l'optimisation du classifier : menu"create edited classifier", ne donnent pas , dans mon cas , de résultats satisfaisants.
TRAITEMENT DES ACCENTSDes règles basées sur la position relative de deux glyphs ont été élaborées pour identifier les caractères accentués qui n'auraient pas été reconnus par la classification features.
Voici par exemple la règle pour le ";" pour le cas où la classification automatique aurait classé "," comme "'" (la confusion entre apostrophe et virgule est fréquente),au dessus d'un point.
elif cible!=None and cible.get_main_id()=="signes.apostrophe" and glyphs_tries[i].get_main_id()=="ponctuation.point" and cible.ul_y-glyphs_tries[i].ul_y <30 and abs(cible.center_x-glyphs_tries[i].center_x)<12:
mon_nouveau=image_utilities.union_images([cible,glyphs_tries[i]])
mon_nouveau.classify_heuristic("ponctuation.point_virgule")
cible.classify_heuristic("_group._part."+cible.get_main_id())
glyphs_tries[i].classify_heuristic("_group._part."+cible.get_main_id())
mon_nouveau.properties={"group":"PPB_165"}
mon_nouveau.properties["fichier"]=string.split(local_nom,'.')[0]
L'utilisation de l'attribut properties permet de garder le souvenir (dans le glyph lui même) de l'application de la règle (utile pour la mise au poin
La propriété 'fichier' ,mémorise pour chaque glyph le numéro de la page du livre contenant ce glyph.
AUTRES GROUPEMENTSLorsque la profondeur des sous graphes dépasse la valeur choisie (pour moi 16) Gamera sort du programme graph; Plusieurs combinaisons pourtant pertinentes ne sont pas explorées par le logiciel.
Je réalise donc une passe supplémentaire en essayant de grouper les glyphs les plus proches du glyph analysé , avec un niveau de confiance au moins égale 40% et meilleur que les confiances d'origine, en mettant dans
properties les références des composants ayant conduit au regroupement.
La suite page suivante....